Overfitting and Underfitting
The cause of poor performance of in machine learning can be attributed to either overfitting or under-fitting. What we want is model that fits appropriately.
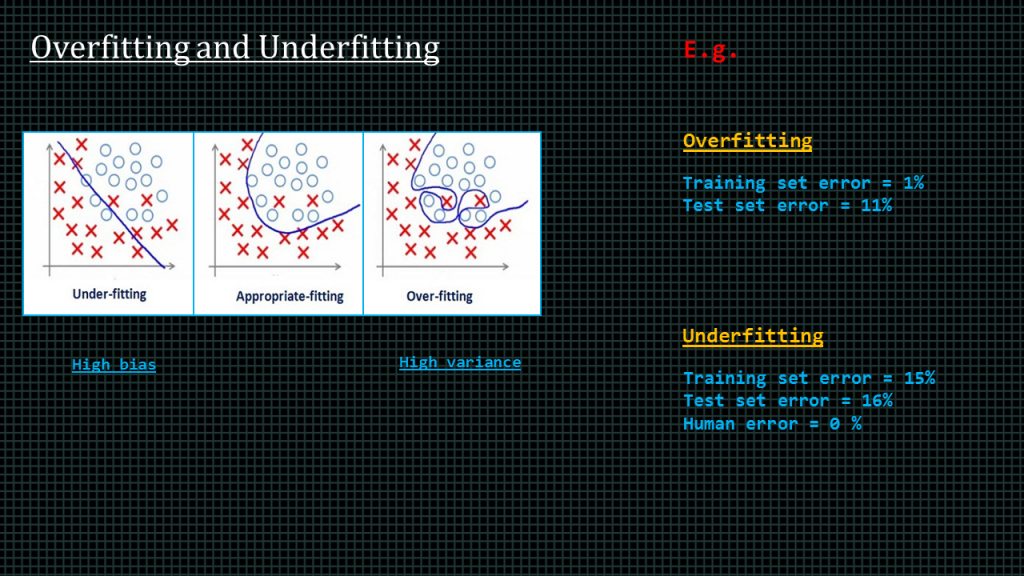
Overfitting happens when a model learns the detail and noise in the training data to the extent that it negatively impacts the performance of the model on new data. This means that the noise or random fluctuations in the training data is picked up and learned as concepts by the model. The problem is that these concepts do not apply to new data and negatively impact the models ability to generalize.
Generalization refers to how well the concepts learned by a machine learning model apply to specific examples not seen by the model when it was learning.
The goal of a good machine learning model is to generalize well from the training data to any data from the problem domain. This allows us to make predictions in the future on data the model has never seen.
In summary, Overfitting refers to a model that models the training data too well.
Underfitting on the other hand refers to a model that can neither model the training data nor generalize to new data.
Ideally, you want to select a model at the sweet spot between under-fitting and overfitting.
This is the goal, but is very difficult to do in practice.
To understand this goal, we can look at the performance of a machine learning algorithm over time as it is learning a training data. We can plot both the skill on the training data and the skill on a test dataset we have held back from the training process.
Over time, as the algorithm learns, the error for the model on the training data goes down and so does the error on the test dataset. If we train for too long, the performance on the training dataset may continue to decrease because the model is overfitting and learning the irrelevant detail and noise in the training dataset. At the same time the error for the test set starts to rise again as the model’s ability to generalize decreases.
The sweet spot is the point just before the error on the test dataset starts to increase where the model has good skill on both the training dataset and the unseen test dataset.
An example of overfitting is when your training set error is 1% and your test error is somewhere around 15%.
An example of under-fitting is your training set error 15%, and your test set error is very large as well, like 15%, and humans are able to make that same prediction with a 0% error. Meaning humans perform 15% better on the training set and 16% better on the test set.
Another name for under-fitting is high bias, and another name for overfitting is high variance.
Let’s see what we can do when we experience either overfitting or under-fitting.
When under-fitting occurs, there are 3-thing we can generally do.
-We can make our neural network bigger
-We can train for a longer time
-We can also try a different neural network.
When overfitting occurs
-we can either get more data,
– apply a method known as regularization
Or try a different neural network.
This is all there is for this lesson. I shall see you later.
Add Comment