Understanding Layers and Nodes
In this lesson we shall talk a bit more about layers and units.
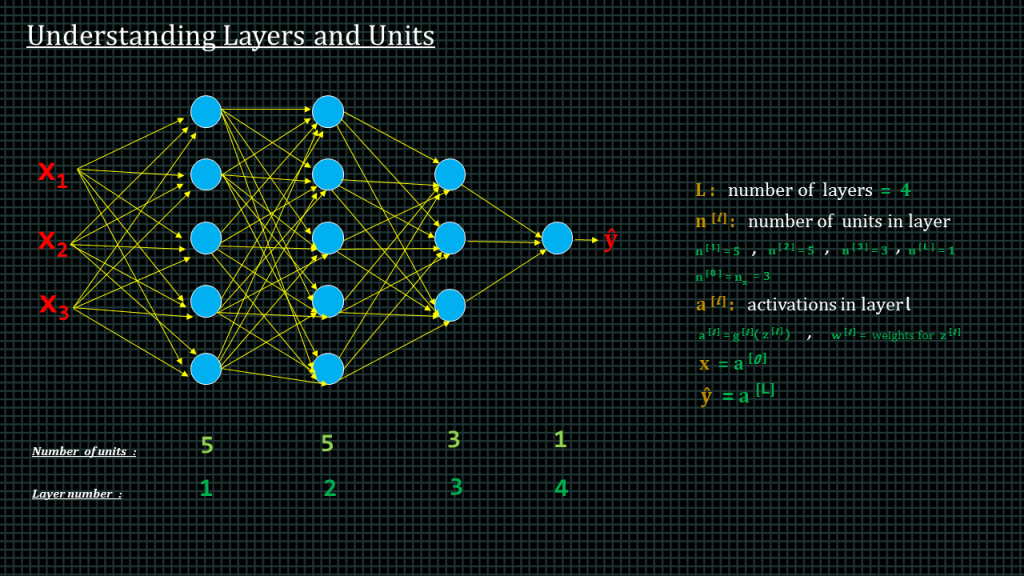
Let’s examine this 4-layer neural network.
This neural network takes 2 inputs.
Layer 1 has 5 units,
Layer 2 has 5 units,
Layer 3 has 3 units and
Layer 4 has 1 unit.
We often denote the number of layers of the neural network with capital “L”
Number of units in a layer is denoted by “n” superscript square bracket “l”, where “l” denotes the layer number.
So that in our current neural network. “n” superscript 1 is equal to 5, “n” superscript 3 is equal to 5, and so on.
We denote activation in layer “l” by “a” superscript square bracket “l”.
The input layer is sometimes referred to as layer “a” superscript 0 and the output layer, which is the same as “yhat” is sometimes denoted as “a” superscript capital “L”.
Now lets talk about the shapes a bit more.
Understanding Shapes
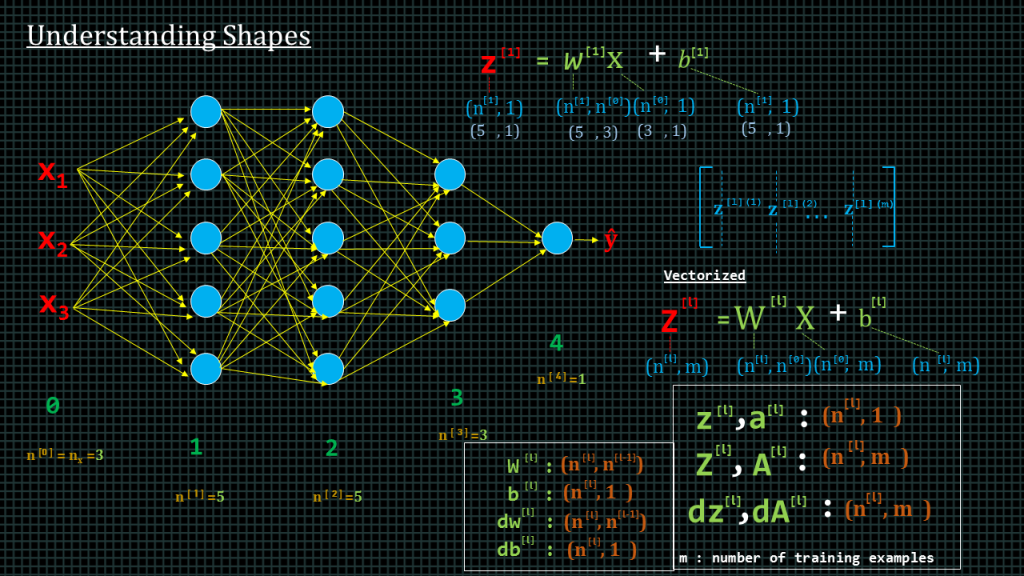
This is our neural network again. The green text here indicate the layer numbers. The orange text indicates the number of units in each layer.
To compute the “z” value of layer1, we compute “z” superscript1 equal to “w” superscript1 “X” plus “b” superscript1.
“x” is a column vector, therefore its shape is 3 by 1,because “w” superscript1 has which is the weight for layer1 has 5 units and each unit is receiving 3 inputs, its shape shall be 5 by 3. “b” superscript 1 is the biase for layer1 which has 5 units. The shape of “b” superscript1 shall be 5 by 1. If we solve this equal with these input shapes the resultant shape which is the shape of “z” superscript1 shall be 5 by 1.
If we denote the shapes with the number of units per layer this is what we get.
We can actually generalize the shapes of the various matrices of our neural network.
To find capital “Z” of layer “l”, which shall contain the “zl” of all training examples, we compute capital “w” layer “l” capital “x” plus “b”.
The shape of capital “X” will be the number of features which we denote as “n” superscript 0 by the number of training examples, which we denote by “m”.
The shape of capital “W” superscript “l”, shall be number of units of layer “l” by number of features or inputs.
The shape of “b” superscript “l” shall be the number of units of layer “l” by the number of examples.
And the shape of capital “Z” superscript l shall be the number of units of layer “l” by training examples.
In summary, the shape of “z” of a single training example of layer “l” written here as small “z” superscript “l” is equal to number of units of layer “l” by 1.
The shape of the “vectorized” version of z, which is written as capital “Z” is equal to number of units in layer “l” by number of training examples, which denoted here as “m”.
The shape of “w” superscript “l” is “n” superscript “l” by “n” superscript “l” minus 1.
The shape of “b” superscript “l” is “n” superscript “l” by 1
The shape of “dw” superscript “l” is the same as the shape of “w” superscript “l”.
The shape of “db” superscript “l” is the same as the shape of “b” superscript “l”. Let’s conclude this lecture by talking about parameters and “hyperparameters”.
Parameters and Hyperparameters
The parameters of our neural network are the weights and biases.
The “hyperparameters” are the parameters we can change in order to improve the performance of our neural network.
These include: learning rate, number of iterations, number of hidden layers, number of hidden units and activation functions.

Add Comment